Web Developer Bootcamp YelpCampでMapTilerを使う その2
上記記事の続きとなります。
一覧ページでMapTilerのCluster Mapを使う
では、キャンプ場一覧画面にてすべてのキャンプ場の位置を地図上に表示する機能を追加しましょう。
参考: MapTiler Documentation - Create and style clusters
いっきに差分を全部知りたい方は以下を参照ください。
フロントエンドの実装
public/javascripts/clusterMap.js の実装
まず、 public/javascripts/clusterMap.js というファイルを新規作成しましょう。中身は以下の内容にしてください。
maptilersdk.config.apiKey = maptilerApiKey; maptilersdk.config.primaryLanguage = maptilersdk.Language.JAPANESE; const map = new maptilersdk.Map({ container: 'cluster-map', style: maptilersdk.MapStyle.BRIGHT, center: [138, 39], zoom: 3, }); map.on('load', function () { console.log('campgrounds', campgrounds) map.addSource('campgrounds', { type: 'geojson', data: campgrounds, cluster: true, clusterMaxZoom: 14, // Max zoom to cluster points on clusterRadius: 50, // Radius of each cluster when clustering points (defaults to 50) }); map.addLayer({ id: 'clusters', type: 'circle', source: 'campgrounds', filter: ['has', 'point_count'], paint: { // Use step expressions (https://docs.maptiler.com/gl-style-specification/expressions/#step) // with three steps to implement three types of circles: 'circle-color': [ 'step', ['get', 'point_count'], '#00BCD4', 10, '#2196F3', 30, '#3F51B5', ], 'circle-radius': [ 'step', ['get', 'point_count'], 15, 10, 20, 30, 25, ], }, }); map.addLayer({ id: 'cluster-count', type: 'symbol', source: 'campgrounds', filter: ['has', 'point_count'], layout: { 'text-field': '{point_count_abbreviated}', 'text-font': ['DIN Offc Pro Medium', 'Arial Unicode MS Bold'], 'text-size': 12, }, }); map.addLayer({ id: 'unclustered-point', type: 'circle', source: 'campgrounds', filter: ['!', ['has', 'point_count']], paint: { 'circle-color': '#11b4da', 'circle-radius': 4, 'circle-stroke-width': 1, 'circle-stroke-color': '#fff', }, }); // inspect a cluster on click map.on('click', 'clusters', async e => { const features = map.queryRenderedFeatures(e.point, { layers: ['clusters'], }); const clusterId = features[0].properties.cluster_id; const zoom = await map .getSource('campgrounds') .getClusterExpansionZoom(clusterId); map.easeTo({ center: features[0].geometry.coordinates, zoom, }); }); // When a click event occurs on a feature in // the unclustered-point layer, open a popup at // the location of the feature, with // description HTML from its properties. map.on('click', 'unclustered-point', function (e) { console.log('features', e.features[0].properties) const { popupMarkup } = e.features[0].properties; const coordinates = e.features[0].geometry.coordinates.slice(); // Ensure that if the map is zoomed out such that // multiple copies of the feature are visible, the // popup appears over the copy being pointed to. while (Math.abs(e.lngLat.lng - coordinates[0]) > 180) { coordinates[0] += e.lngLat.lng > coordinates[0] ? 360 : -360; } new maptilersdk.Popup() .setLngLat(coordinates) .setHTML(popupMarkup) .addTo(map); }); map.on('mouseenter', 'clusters', () => { map.getCanvas().style.cursor = 'pointer'; }); map.on('mouseleave', 'clusters', () => { map.getCanvas().style.cursor = ''; }); });
views/campgrounds/index.ejs の実装
次に詳細画面のとき同様に views/campgrounds/index.ejs にて maptilerApiKey やキャンプ場の一覧の情報として campgrounds を準備します。
以下を末尾に追加しましょう。
<script> const maptilerApiKey = "<%- process.env.MAPTILER_API_KEY %>"; const campgrounds = { type: "FeatureCollection", features: <%- JSON.stringify( campgrounds.map(campground => ({ type: "Feature", geometry: campground.geometry, properties: { popupMarkup: campground?.properties?.popupMarkup } })) ) %> }; </script> <script src="/javascripts/clusterMap.js"></script>
前回同様、上記コードに関しても <script> の順番を変えないでください。 maptilerApiKey も campgrounds も /javascripts/clusterMap.js で使うからです。
さらに、地図を表示する場所を確保したいので、 <div id="cluster-map" style="width: 100%; height: 500px"></div> も追加しましょう。 <% layout('layouts/boilerplate') %> 直下に追加してください。
<% layout('layouts/boilerplate') %> <!-- ↓↓↓ここを追加 --> <div id="cluster-map" style="width: 100%; height: 500px"></div> <!-- ↑↑↑ここを追加 --> <h1>キャンプ場一覧</h1> <div> <a href="/campgrounds/new">新規登録</a>
バックエンドの実装
では、地図上の●をクリックしたときに表示するポップアップが出せるようにバックエンドの実装を調整しましょう。

models/campground.js の実装
// ↓↓↓ここを追加 const opts = { toJSON: { virtuals: true } }; // ↑↑↑ここを追加 const campgroundSchema = new Schema({ title: String, images: [imageSchema], // 省略 }, opts); // ←ここのoptsを追加 // ↓↓↓ここを追加 campgroundSchema.virtual('properties.popupMarkup').get(function () { return `<strong><a href="/campgrounds/${this._id}">${this.title}</a></strong> <p>${this.description.substring(0, 20)}...</p>` }); // ↑↑↑ここを追加
参考: Mongoose Documentation - Virtuals
うまくいけば以下のようにキャンプ場一覧にCluster Mapが表示されます!

Web Developer Bootcamp YelpCampでMapTilerを使う その1
Web Developer BootcampのYelpCampアプリにてMapBoxを使用していたのですが、無料範囲内で使う場合であってもクレジットカードの登録が必須となりました。YelpCampでの使用に閉じていればまず無料枠を超えることが無いのでクレジットカードの登録を行っても良いのですが、不安に思う人も少なくないはず。
ということで、MapBoxの代わりに使うことのできるMapTilerを使用した方法についてこの記事で紹介します。
前提として Web Developer Bootcamp の 「セクション55: YelpCamp: 地図の追加」まで進んでいることとします。あくまでこの記事は「MapBoxのコードをMapTilerに置き換えた場合どうなるのか」を説明するものになっています。
とにかく修正が必要なコードをいっきに見たいという人は以下を参照ください。
ステップ1 MapTilerでユーザー登録
まず https://www.maptiler.com/ にアクセスします。「CREATE FREE ACCOUNT」をクリックしましょう。

Googleアカウントがある人はGoogleで登録を行い、持っていない人はメールアドレスで登録しましょう。

アンケートのポップアップが出てくるので必要に応じて答えましょう。

ステップ2 MapTilerのAPIキー確認
MapTilerにログインできたらAPIキーのページに行きましょう: https://cloud.maptiler.com/account/keys/
そこにデフォルトのAPIキーが既にあるはずなのでコピーしましょう。

このAPIキーをYelpCampプロジェクトの .env ファイルに設定します。ここまでのセクションでCloudinaryの設定をする際にこのファイルは作成済みのはずです。以下のように MAPTILER_API_KEY を設定しましょう。
MAPTILER_API_KEY=<ここにコピーしたAPIキーを貼り付け>
MAPTILER_API_KEY という文字列は絶対に間違えないようにしましょう。
ステップ3 MapTilerをコードから使えるようにする
以下のコマンドをターミナルで実行し、MapTilerがコードで使えるようにします。
npm install @maptiler/client@2.5.0
- 関連ドキュメント
詳細ページでMapTilerの地図を使う
ステップ4 バックエンドの実装
controllers/campgrounds.js の実装
以下のコードをファイルの先頭に追加しましょう。 @maptiler/client を初期化します。
const maptilerClient = require("@maptiler/client"); maptilerClient.config.apiKey = process.env.MAPTILER_API_KEY;
createCampground のControllerにて以下のコードを追加します。「ここを追加」と書いている部分になります。
module.exports.createCampground = async (req, res) => { // ↓↓↓ここを追加 const geoData = await maptilerClient.geocoding.forward( req.body.campground.location, { limit: 1 } ); // console.log(geoData); // ↑↑↑ここを追加 const campground = new Campground(req.body.campground); // ↓↓↓ここを追加 campground.geometry = geoData.features[0].geometry; // ↑↑↑ここを追加 campground.images = req.files.map(f => ({ url: f.path, filename: f.filename })); campground.author = req.user._id; await campground.save(); console.log(campground); req.flash('success', '新しいキャンプ場を登録しました'); res.redirect(`/campgrounds/${campground._id}`); }
models/campground.js の実装
次に campgroundSchema に geometry の情報を追加します。MapTilerのAPIから取得するキャンプ場の地理情報をデータベースに保存するためです。Mongooseで地理情報を保存するときには以下の形で保存する必要があります。
geometry: { type: { type: String, enum: ['Point'], required: true }, coordinates: { type: [Number], required: true } }
参考: Mongoose Documentation - Using GeoJSON
よって、完全な campgroundSchema の形は以下のようになります。
const campgroundSchema = new Schema({ title: String, images: [imageSchema], // ↓↓↓ここを追加 geometry: { type: { type: String, enum: ['Point'], required: true }, coordinates: { type: [Number], required: true } }, // ↑↑↑ここを追加 price: Number, description: String, location: String, author: { type: Schema.Types.ObjectId, ref: 'User' }, reviews: [ { type: Schema.Types.ObjectId, ref: 'Review' } ] });
ステップ5 フロントエンドの実装
views/layouts/boilerplate.ejs の実装
では、MapTilerのSDKを使ってフロントエンドで地図が表示できるようにしましょう。まずは以下のコードを boilerplate.ejs の <head> の中に追加します。
<title>YelpCamp</title> <link href="https://cdn.jsdelivr.net/npm/bootstrap@5.1.0/dist/css/bootstrap.min.css" rel="stylesheet" integrity="sha384-KyZXEAg3QhqLMpG8r+8fhAXLRk2vvoC2f3B09zVXn8CA5QIVfZOJ3BCsw2P0p/We" crossorigin="anonymous"> <!-- ↓↓↓ここを追加 --> <script src="https://cdn.maptiler.com/maptiler-sdk-js/v3.6.1/maptiler-sdk.umd.min.js"></script> <link href="https://cdn.maptiler.com/maptiler-sdk-js/v3.6.1/maptiler-sdk.css" rel="stylesheet" /> <!-- ↑↑↑ここを追加 --> </head>
参考: MapTiler Documentation - MapTiler SDK JS
public/javascripts/showPageMap.js の実装
まず、 public/javascripts/showPageMap.js というファイルを新規作成しましょう。中身は以下のようにします。これでひとまずMapTilerが使える状態にします。
maptilersdk.config.apiKey = maptilerApiKey; // 地図は日本語にしたいので日本語の設定を入れておく maptilersdk.config.primaryLanguage = maptilersdk.Language.JAPANESE; const map = new maptilersdk.Map({ container: 'map', style: maptilersdk.MapStyle.BRIGHT, center: campground.geometry.coordinates, // starting position [lng, lat] zoom: 10, // starting zoom }); new maptilersdk.Marker() .setLngLat(campground.geometry.coordinates) .setPopup( new maptilersdk.Popup({ offset: 25 }).setHTML( `<h3>${campground.title}</h3><p>${campground.location}</p>` ) ) .addTo(map);
- 参考
views/campgrounds/show.ejs の実装
MapTilerを使うためにAPIキーを渡し、キャンプ場の情報も渡します。よって、以下のようなコードを views/campgrounds/show.ejs の末尾に追加しましょう。
<script> const maptilerApiKey = '<%- process.env.MAPTILER_API_KEY %>'; const campground = <%- JSON.stringify(campground) %>; </script> <script src="/javascripts/showPageMap.js"></script>
【注意点】
上記コードの <script> の順番は変えないでください。 /javascripts/showPageMap.js で maptilerApiKey や campground の変数を使うため、先に宣言しておく必要があります。
最後に、以下のように <div id="map" style="width: 100%; height: 300px"></div> を追加して、地図が表示される場所を確保しましょう。2個目の <div class="col-6"> の直下です(「レビュー」がある場所です)
<div class="col-6"> <!-- ↓↓↓ここを追加 --> <div id="map" style="width: 100%; height: 300px"></div> <!-- ↑↑↑ここを追加 --> <% if(currentUser) { %> <h2>レビュー</h2> <form action="/campgrounds/<%= campground._id %>/reviews" method="POST" class="mb-3 validated-form" novalidate>
ここまでの修正が完了すれば、キャンプ場を登録した際に以下のように地図が表示されるようになります!

続きは以下の記事となります。
Vertical Slice Architecture について
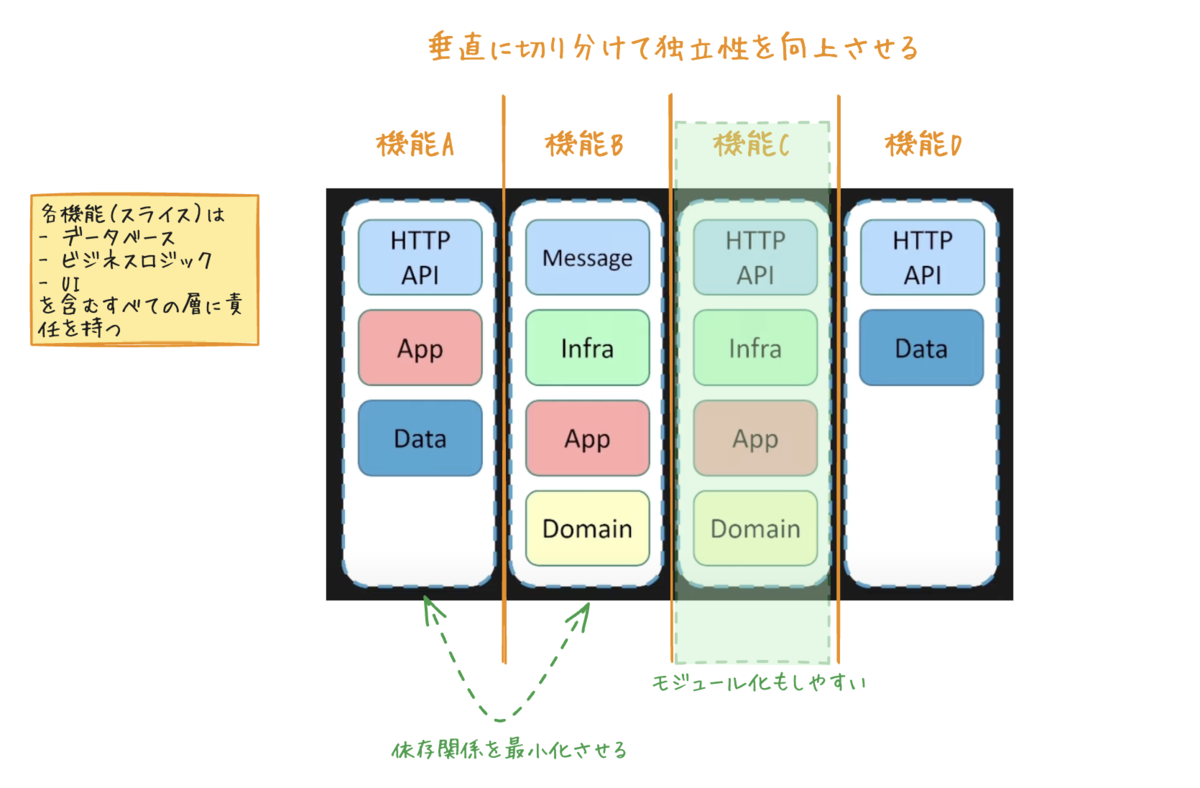
Vertical Slice アーキテクチャとは?
- 垂直的な切り分け:システムを機能ごとに縦に分割し、各機能が独立して開発・デプロイできるアーキテクチャ。
- 横断的な切り分けとの違い:従来のレイヤードアーキテクチャ(プレゼンテーション、ビジネスロジック、データ層など)とは異なり、特定の機能を全レイヤーで完結させるアプローチ。
- 独立性の向上:機能が独立しているため、変更や拡張が容易。
Vertical Slice のメリット
- モジュール化:特定のビジネスロジックや機能に関わる部分のみを開発することで、システム全体に影響を与えずに作業できる。
- テスト容易性:各スライスごとに独立したテストが可能で、問題の特定がしやすくなる。
- スケーラビリティ:特定の機能に対してスケールさせやすい。
どうやって実装するのか?
- 機能ごとの責任範囲:各機能(スライス)はデータベース、ビジネスロジック、UIを含むすべての層に責任を持つ。
- 独立したデプロイ:Microservices アーキテクチャとも似ており、各スライスを別々にデプロイ可能にすることで、柔軟な運用が可能。
Vertical Slice の設計原則
- シンプルさ:不要なレイヤーや抽象化を避け、実際に必要なものだけを使う。
- 集中した関心事:1つのスライスが1つの機能に集中することで、コードの可読性とメンテナンス性を向上させる。
- 依存関係の最小化:他のスライスやモジュールへの依存を減らし、独立して動作させることが重要。
他のアーキテクチャとの比較
- レイヤードアーキテクチャ:レイヤードアーキテクチャは各レイヤー(UI、ビジネスロジック、データ)が独立しているが、依存関係が複雑になりやすい。
- モノリシックアーキテクチャ:システム全体を1つの大きなブロックとして扱うため、変更やスケーリングが難しい。
- Microservices:Vertical Slice は Microservices に似ているが、必ずしも分散システムではなく、1つのアプリ内でも使用可能。
結論
- 柔軟でスケーラブル:Vertical Slice アーキテクチャは、システム全体を柔軟にし、必要な部分だけを変更・拡張できる。
- 開発の効率化:個別の機能をモジュール化しやすく、開発のスピードや品質を向上させる。
ハイライト 2023-04-19

Articles
LangChain x Supabase
- LangChainとSupabaseは、GPT-3のようなモデルとPrivateなデータをつなげたり、ドキュメントのembeddingをvector storeに格納したりと、複数の方法で一緒に使うことができる
- LangChainとSupabaseを併用することで、フルスタックのAIアプリケーションが作れる
- LangChain and Supabase Starter Templateは、React + Next.js + Tailwindのフロントエンドと、セットアップとデプロイの手順、LangChainを使ってGPT-3.5のAPIを呼び出すSupabase Edge Functionを提供。
- LangChainは最近Deno上での実行をサポートするようになり、Supabase Edge Functionsと一緒に使うことができる
他人の10倍仕事ができる人に10倍の給与を支払うべきなのか問題
- プログラマーの能力に基づく給与の議論についての記事
- 優秀なプログラマーは他の人より10倍も仕事ができるが、その分だけ給料をもらうべきかについての問題
- 最終的に、給与を決定する際には、相互に合意できる評価基準を見つけることが必要
後で楽できるTerraformの書き方(※ただし書くときは辛い)
- Terraformのコードを簡素化し、読みやすくするためのコーディングガイドラインを紹介しています。
An example of LLM prompting for programming
- Generated Knowledgeと呼ばれるプロンプト技法を使ってインタラクションを別のステップに分割
- Generated Knowledgeは、2つのスタイルのプロンプトを組み合わせる
- Instruction prompting
- Chain of Thought prompting
- LLMとパートナーのように、設計のガイドラインから始めて、その根拠を示してもらい、アウトプットに手を加えながら活用するのが有用
Private SaaS Is Coming: Are You Ready?
- Public Cloudは、過去20年以上にわたってソフトウェア展開を変革してきましたが、完全に制御できるPrivateな環境を必要とするニーズは依然として一定存在する
- セキュリティ、管理、監査、コンプライアンスなど、さまざまな業界の企業がプライベートSaaSでのサービスを求めるようになっている
- プライベートSaaSは、SaaSの利点を享受しながらも、複雑なセキュリティ要件を満たし、それを超えることができるようにする
Videos
Connect OpenAI To +5,000 Tools (LangChain + Zapier)
- LangChainとZapierを使ってOpenAIを+5,000のツールに接続
- Zapierの自然言語APIを使ってOpenAIと対話す
- ツイートの作成、メールの下書き、Slack、Giphy、Gmailなどへのメッセージの送信。
- メールの要約、ツイートの作成、Gmailでの下書きの実行例
Structured Output From OpenAI (Clean Dirty Data)
- OpenAIモデルは、非構造化の入力を受け取り、構造化された出力を生成するために使用できる
Tweets
I read all 154 pages of Microsoft Research's "Sparks of AGI".
— Alex Banks (@thealexbanks) 2023年4月16日
Most people don't realise the shocking reality AI is going to bring.
Here's what I found:
ハイライト 2023-04-12

Books
The Staff Engineer's Path: Chapter 1. What Would You Say You Do Here?
- スタッフエンジニアの役割は曖昧で、自分で役割を見つけ、決める必要がある
- 役割の範囲を明確にし、価値あるものと実用的なものを理解する
- すでにシニアが多いプロジェクトを選ぶときには注意する
- シニアじゃないエンジニアの機会を奪ってしまっていないか
- 会社にとって重要なことに時間を費やすことを意識的に行う
- 自分の時間は自分で守る
- 品質、効率、秩序を維持し、ソフトウェアが機能するようにシニアが必要
- シニアエンジニアは、マネージャーまたはスタッフエンジニアに昇格するスキルを身につける選択ができる
Videos
The LangChain Cookbook - Beginner Guide To 7 Essential Concepts
- LangChain Cookbookは以下7つの言語モデル開発のための基本概念を紹介する初心者向けガイド
Tweets
These graphics summarize some of life's hardest lessons.
— Nicolas Cole 🚢🏴☠️ (@Nicolascole77) 2023年4月10日
1/ Distractions fill the space we give them. pic.twitter.com/MIZvysCkSo
- Distractions fill the space we give them.
- Empathy lifts you and the other person up; judgment pulls you and the other person down.
- Repetition is the father of learning.
- Proficiency is just pattern recognition.
- The goal is to grow forever, not to grow fast.
- Action is the only thing between you and your future self.
- Set your own priority list to avoid being dictated by others.
- Create and play your own game rather than competing in someone else's.
- Focus on doing something you are intrinsically interested in, rather than something that is popular but you hate.
- Fundamentals are the doorway to mastery.
If you’re an “AI builder” and not personally spending at least $100 a month exploring latent space, you may not be trying hard enough.
— swyx 🌉 (@swyx) 2023年4月11日
(this is a note to self, and a wake up call. I spent $2 on @OpenAI last month and I genuinely think that is a problem)
自分もAI関連のものに投資していかないとなー
I asked ChatGPT to buy my groceries today using @Instacart’s plug-in and it worked so well!
— Ammaar Reshi (@ammaar) 2023年4月11日
- Stayed within my budget
- Provided ingredients and recipes for 7 meals (including some favorites!)
- Accounted for my schedule and diet
Here’s the convo and delivered groceries 🤩 pic.twitter.com/omRylk13LS
料理考えてもらうのとか、買い物するものの提案とか、実用性めちゃ高そう
ハイライト 2023-04-05
Articles
Staff archetypes
- スタッフエンジニアには4つのタイプがある
- Tech Lead
- チームをリードする責任がある
- Architect
- 企業内の特定の技術領域の成功に責任を持つ
- Solver
- 組織の信頼されていて複雑な問題に深く関わる
- Right Hand
- 直接の管理責任を持たない上級組織リーダーに似ていて、リーダーのスタッフミーティングに出席してリーダーたちの影響力を拡大させる
- Tech Lead
先日 Wantedly さんのエンジニアリングマネージャー座談会に出…
- 開発生産性に関しては、ディスカバリーとデリバリーの2軸で考える
- デリバリーの強さがディスカバリーの強さを引っ張り上げる
- 開発チームを改善するためには、高速にアウトプットしリリースを繰り返せるチームを目指す
- そのためには、各軸(デリバリー、ディスカバリー)それぞれ80点を取ることを目指す
- チームを改善するためには、イテレーションを回してコミュニケーションのトラブルを解決し、改善された実感を得るのが重要
- 良い企画が当たったときには爆速でリリースする
You Are Not Too Old (To Pivot Into AI)
- 挑戦する姿勢を忘れずに改善あるのみ!
Learn In Public
- 学びは公にする習慣をつける
- 正しいことをすることを心がけるが、間違った時には悩まずに自分が初心者であることを表明する
- 教えることが学ぶための最良の方法であり、コードを書きながら話をすることも重要
Pick Up What They Put Down
- 「pick up what they put down」という方法で、自分が尊敬する人が公開した新しいライブラリ、デモ、動画、ポッドキャスト、書籍、ブログ記事、またはコースを見つける。
- 見つけたものに基づいてコンテンツを作成し、それに本当に興味を持ち、熱中して取り組むことが重要。
- ソーシャルメディアで自分が作成したコンテンツのクリエイターにタグ付けし、フィードバックやエンドースメントを受け取る準備をする。
- 習慣を形成するために、トリガー、アクション、可変報酬、投資のフックドモデルに従う。
- 興味を持つものを3つ選び、そのうちの1つについてフィードバックを受ける。これを12回繰り返すことで、多くのことを学び、多くの新しい友達を作ることができる。
Growth of AI Through a Cloud Lens
- 最近のAIの動きが、クラウドが出てきた頃と似ている
- クラウドの主な利点は、既存のソフトウェアを移行できる能力であり、AIにも同じ利点がある
- AIのバズり方はクラウドよりも広い社会的影響力があり、成熟期間がクラウドのときよりも短くなることが予想される
GPT-4時代のエンジニアの生存戦略
- これにつきます→『エンジニアとして、「顧客/ユーザーがほしいと言っているもの」を定義済みの要件からコードを書いて作るのではなく「ビジネスサイドがそれにより実現したいこと」を探り当て、コーディングを手段として扱うことができれば、科学的、批判的思考スキルを必要とする職業となり、GPTは仕事を奪う敵では無く有能な味方として扱えるようになります。』
Tweets
ChatGPT is free education.
— Alex Brogan (@_alexbrogan) 2023年3月30日
But 99% don’t know the best prompts on its virtual campus.
Here are the top prompts to accelerate your learning:
テンプレにして何かを学ぶときに使える
Not having a ChatGPT plugin will be like not having a mobile app or website.
— Mckay Wrigley (@mckaywrigley) 2023年3月26日
Every business will need one.
There is a *massive* opportunity to help onboard businesses to AI.
Take advantage.
ChatGPT Pluginが気になる
ハイライト 2023-03-29
Books
Software Architecture: The Hard Parts - 10. Distributed Data Access
- Column Schema Replication Pattern
- 列がテーブル間で複製され、データが他のBounded Contextで利用可能になる
- データ同期とデータの整合性が問題になる
- データのOwnershipも難しい
- Replicated Cache Pattern
- 複製されたインメモリキャッシュを利用し、他のサービスで必要なデータを各サービスで利用可能にする
- データは各サービス内のメモリに保持され、常に同期されるため、すべてのサービスで正確なデータを持つ
- データ同期と整合性が最大の問題
- 障害耐性、パフォーマンス、外部キャッシュ依存のないところが利点
- Data Domain Pattern
- 別サービスのデータを同じSchemaで管理しちゃう
- 構造が変更された場合、データドメインのテーブルのいずれかの構造が変更された場合、複数のサービスが変更する必要がある
Tweets
Not having a ChatGPT plugin will be like not having a mobile app or website.
— Mckay Wrigley (@mckaywrigley) 2023年3月26日
Every business will need one.
There is a *massive* opportunity to help onboard businesses to AI.
Take advantage.
ChatGPT Plugin試してみたいなー